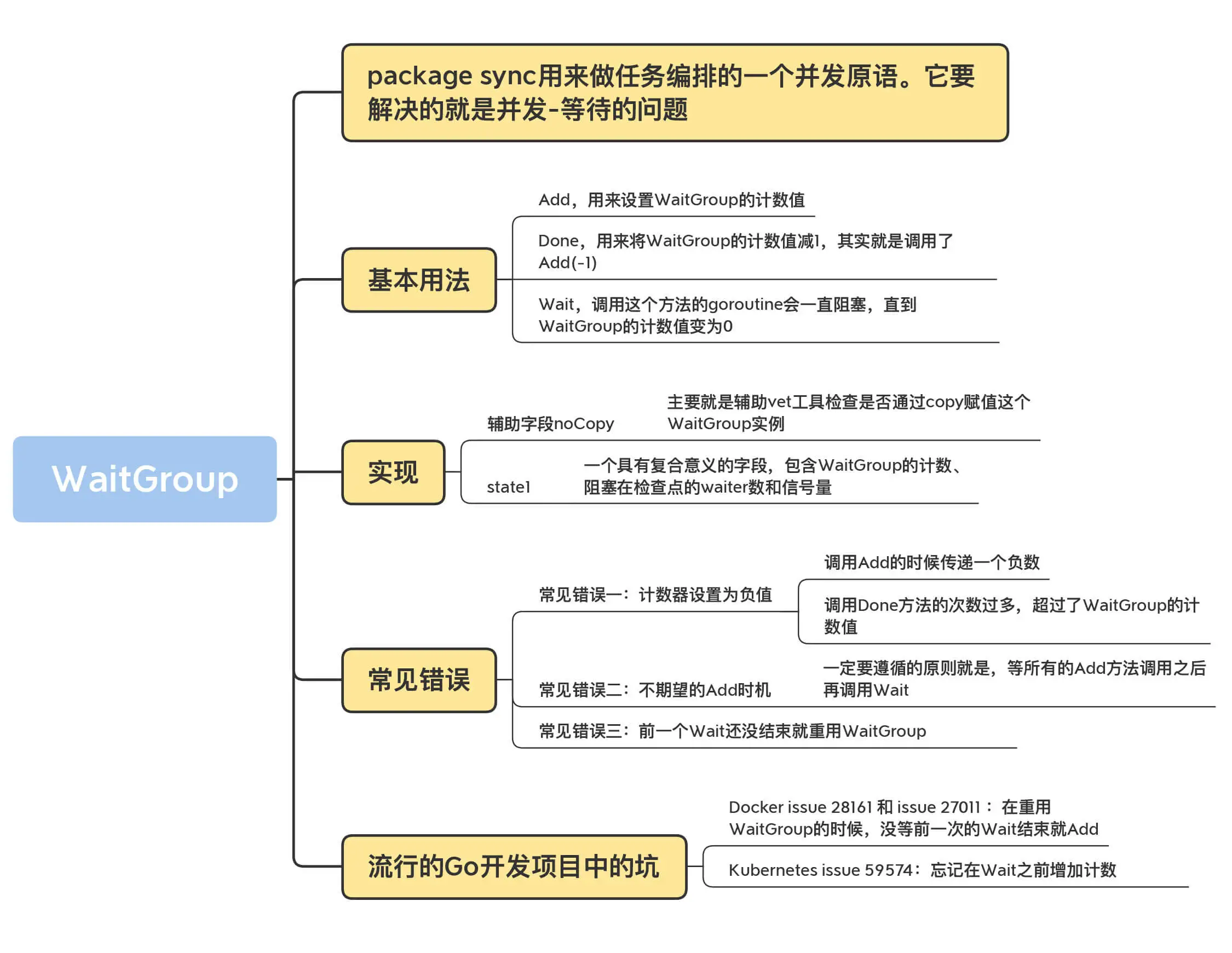
基本用法
Go 标准库中的 WaitGroup 提供了三个方法:
1 | func (wg *WaitGroup) Add(delta int) // 用来设置 WaitGroup 的计数值 |
下面是一个使用示例,WaitGroup的值设置为10,然后在 10 个协程中完成计数,然后执行 wg.Done()。最后 wg.Wait() 等待 goroutine 都完成任务。
1 |
|
实现原理
数据结构
WaitGroup 的数据结构。包括了一个 noCopy 的辅助字段,一个 state1 记录 WaitGroup 状态的数组。
- noCopy 的辅助字段,主要就是辅助 vet 工具检查是否通过 copy 赋值这个 WaitGroup 实例。
- state1,一个具有复合意义的字段,包含 WaitGroup 的计数、阻塞在检查点的 waiter 数和信号量。
1 |
|
内存对齐
这段代码主要是用来判断
WaitGroup实例的状态变量state1是否为 8 字节对齐的。在 Go 中,如果一个变量的地址是 8 的倍数(即 8 字节对齐),则称之为“自然对齐”;否则,需要通过填充字节使其对齐。这是因为在某些处理器架构上,未对齐的访问会导致性能问题或者崩溃。在
state()方法中,我们首先使用unsafe.Pointer把state1的地址转换成指针类型,再使用uintptr将指针转换成整数类型。然后,我们检查整数值是否为 8 的倍数。如果是,说明state1已经自然对齐了;否则,说明state1不是 8 字节对齐的,我们需要调整偏移量来让它对齐。对于已经自然对齐的情况,我们直接返回高 64 位和低 32 位的指针即可。对于未对齐的情况,我们将高 64 位的指针偏移 1,得到真正的起始位置;将低 32 位的指针指向空间的第一个字节(即
state1[0])即可。
当我们定义一个结构体时,编译器会根据结构体成员的大小和类型在内存中分配一段连续的空间。例如,假设我们定义了如下的一个结构体:
2
3
4
5
> A int32
> B bool
> }
>
在 64 位的系统中,
int32类型的大小为 4 字节,而bool类型的大小为 1 字节。因此,编译器在内存中为这个结构体分配了 8 个字节的空间,其中前 4 个字节存储A,后 1 个字节存储B,还有 3 个字节没有被使用。在某些情况下,如果结构体的大小不是 8 的倍数(即结构体没有对齐到机器字长的边界),则需要进行填充字节,从而保证结构体在内存中对齐。例如,如果我们定义了如下的一个结构体:
2
3
4
5
6
> A int32
> B bool
> C int16
> }
>
在 64 位的系统中,
int32类型的大小为 4 字节,bool类型的大小为 1 字节,而int16类型的大小为 2 字节。因此,编译器在内存中为这个结构体分配了 12 个字节的空间,其中前 4 个字节存储A,接下来的 1 个字节存储B,然后是两个字节的填充,最后 2 个字节存储C。可以看到,由于
MyStruct2的大小不是 8 的倍数,因此需要添加两个字节的填充。这样,在内存中,MyStruct2在地址上就自然对齐了,从而避免了访问未对齐内存的性能问题或者错误。类似地,在
sync.WaitGroup类型中,如果state1变量不是 8 字节对齐的,那么需要进行填充,从而保证指向计数器和信号量的指针能够正确访问
为什么32bit系统的处理上,state1的元素排列和64bit的不同呢
64bit : waiter,counter,sem
32bit : sem,waiter,counter
首先要理解的是内存对齐,32 位机和 64 位机的差别在于每次读取的块大小不同,前者一次读取 4 字节的块,后者一次读取 8 字节的块。
WaitGroup的大小是 12 字节,接下来我声明了一个var wg sync.WaitGroup,假设此处 wg 的内存地址是 0xc420016240,此时这个地址是 64bit 对齐的,因此这里的重点是不论是 32 位机器还是 64 位机器,state1 的元素排列都是waiter,counter,sem。wg 的地址空间是0xc420016240~0xc42001624c,因此如果此时是 64 位机的话还有4字节的空间可以分配给其他大小合适的变量。那此时 state1 的排列能不能是sem,waiter,counter呢?不能,因为 64 bit 值的原子操作必须 64 bit 对齐。 对于 32 位机器就会有一种特殊情况,那就是 wg 的内存地址起始被分配到了 0xc420016244,此时这个地址不是 64 bit 对齐的,因此这个时候排列变成了sem,waiter,counter,这样的话,waiter的起始地址变成了 0xc420016248,可以使用 64 bit 值的原子操作。
如果内存地址不是64位对齐,则让seman填充第一个32位,这样子就可以使得后面的state以64位对齐(因为state存储的两个值要同步修改)。
Add,Done
Add 方法主要操作的是 state 的计数部分。你可以为计数值增加一个 delta 值,内部通过原子操作把这个值加到计数值上。需要注意的是,这个 delta 也可以是个负数,相当于为计数值减去一个值,Done 方法内部其实就是通过 Add(-1) 实现的
1 |
|
Wait
Wait 方法的实现逻辑是:不断检查 state 的值。如果其中的计数值变为了 0,那么说明所有的任务已完成,调用者不必再等待,直接返回。如果计数值大于 0,说明此时还有任务没完成,那么调用者就变成了等待者,需要加入 waiter 队列,并且阻塞住自己。
1 |
|
常见错误
计数器设置为负值:一般情况下,有两种方法会导致计数器设置为负数。第一种方法是:调用 Add 的时候传递一个负数。如果你能保证当前的计数器加上这个负数后还是大于等于 0 的话,也没有问题,否则就会导致 panic。第二个方法是:调用 Done 方法的次数过多,超过了 WaitGroup 的计数值。
不期望的 Add 时机:一定要遵循的原则,等所有的 Add 方法调用之后再调用 Wait。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
func main() {
var wg sync.WaitGroup
go dosomething(100, &wg) // 启动第一个goroutine
go dosomething(110, &wg) // 启动第二个goroutine
go dosomething(120, &wg) // 启动第三个goroutine
go dosomething(130, &wg) // 启动第四个goroutine
wg.Wait() // 主goroutine等待完成
fmt.Println("Done")
}
func dosomething(millisecs time.Duration, wg *sync.WaitGroup) {
duration := millisecs * time.Millisecond
time.Sleep(duration) // 故意sleep一段时间
wg.Add(1)
fmt.Println("后台执行, duration:", duration)
wg.Done()
}上述代码中,主 goorutine 调用 Wait 的时候,因为四个任务 goroutine 一开始都休眠,所以可能 WaitGroup 的 Add 方法还没有被调用,WaitGroup 的计数还是 0,所以它并没有等待四个子 goroutine 执行完毕才继续执行,而是立刻执行了下一步。导致这个错误的原因是,没有遵循先完成所有的 Add 之后才 Wait。
前一个 Wait 还没结束就重用 WaitGroup:只要 WaitGroup 的计数值恢复到零值的状态,那么它就可以被看作是新创建的 WaitGroup,被重复使用。但是,如果我们在 WaitGroup 的计数值还没有恢复到零值的时候就重用,就会导致程序 panic。
1
2
3
4
5
6
7
8
9
10
11
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
time.Sleep(time.Millisecond)
wg.Done() // 计数器减1
wg.Add(1) // 计数值加1
}()
wg.Wait() // 主goroutine等待,有可能和 wg.Add(1) 并发执行, 就会导致程序 panic
}WaitGroup 虽然可以重用,但是是有一个前提的,那就是必须等到上一轮的 Wait 完成之后,才能重用 WaitGroup 执行下一轮的 Add/Wait,如果你在 Wait 还没执行完的时候就调用下一轮 Add 方法,就有可能出现 panic。
总结